微大智能科技(苏州)有限公司
所谓3D视觉定位指的是根据事先构建的3D模型及相关信息,计算取得某张图像在拍摄时相机的位置和姿态。这是3D视觉的一项十分重要的技术,可以用来帮助实现人员定位与导航。本博文将基于2019年CVPR论文From Coarse to Fine: Robust Hierarchical Localization at Large Scale所采用的分级定位方案对该技术进行简要的介绍。
基本原理
3D视觉定位的直接目标是计算当前图像的照相机位姿,解决该问题的直接方案是建立3D点与2D点之间的匹配关系,通过二者的匹配关系估计相机位姿,这一问题被称作PnP(Pespective-n-Point)问题。求解PnP问题的方法有很多,常见的有P3P、EPnP、UPnP等,具体的如何实现本文不做介绍,读者可以自行搜索PnP问题的相关理论。而视觉定位需要解决的一大关键问题是如何建立3D点与2D点之间的匹配关系。对于这一点,论文作者Sarlin提出过一种分级定位的方案,以下将详细介绍该方案。
分级定位
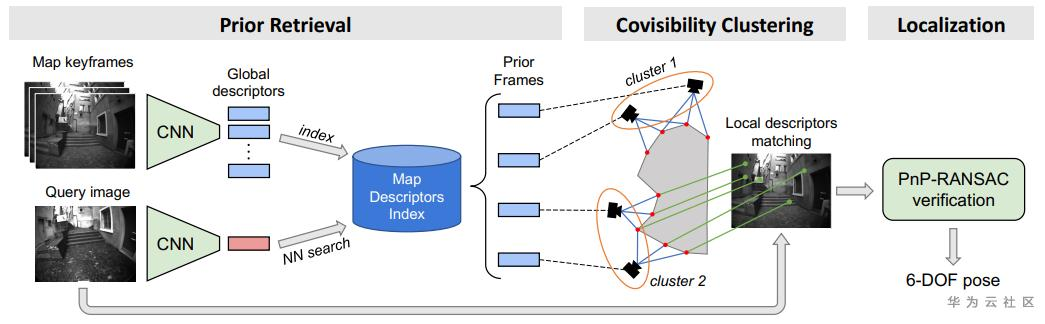
分级定位的框架大约可以分成三步:预检索、共视聚类、局部匹配与定位。
预检索
预检索的意义在于获取前k张与当前图像最相似的图像,判断相似的依据通常是通过匹配图像的全局特征。一般而言,产生全局特征的方法可以依赖于局部特征所组成的词袋,不过近些年,一些深度学习方案也被引入了进来,例如NetVLAD或更加轻量级的MobileNetVLAD。最终通过获取当前图像的全局特征的k个最近邻来获取预检索得到的相近图集。
共视聚类
然而由于可能产生的错误匹配,所获取到的预检索图集并不一定全部都面向同一场景,这时就需要先将面向不同场景的图像区分开来,这项技术就被称作共视聚类,简而言之就是将具有共视关系的图像聚成一类。
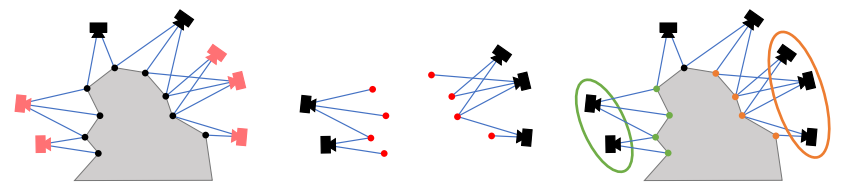
这一过程实际十分简单,它是通过匹配同名点来获取的,这些同名点在早先进行的3D建模过程中通过特征的提取与匹配已经建立了对应的关系。若两个图像中存在稳定的同名点,则认为二者共视,分成一类,否则分成两类。
局部匹配与定位
一般认为图像数量较多的类所对应的场景是正确场景的可能性较大。因此从这一场景开始,尝试获取相机位姿。获取的方式主要依赖求解PnP问题,因此需要首先构建当前图像的2D关键点在3D模型中的坐标位置。在尚不知道相机姿态前,这一信息的获取需要首先匹配当前图像和场景内的图像,特别要匹配那些能够对应到3D位置的2D特征点,若能够匹配上则确定了当前图像中的2D点和3D点的对应关系,继而即可通过对PnP问题的求解获取相机位姿。
总结
本博文基于当前被广泛采用的分级视觉定位方法对在3D视觉领域广泛使用的视觉定位方法进行了简要介绍,其主要可以被分为三个步骤,即预检索、共视聚类、局部匹配与定位,最终通过求解PnP问题来获取当前图像的位姿,从而确定拍摄者的位置。笔者后续将继续保持对3D视觉领域的研究和关注,并继续输出相关博文。
